

In Elixir, once you have clustering set up, it's ridiculously easy to run some code on another node in your cluster:
Node.spawn(:"[email protected]", fn ->
# This runs on a different node
send(self(), node())
end)
receive do
response -> IO.puts "Got response: #{response}"
after
5000 -> IO.puts "No response after 5 seconds"
endBut instead of having to hard-code node names and adding receive messages sent by spawned processes, I wanted a slightly nicer API.
FLAME, but without autoscaling
I find the FLAME API to be very intuitive:
def generate_thumbnails(%Video{} = vid, interval) do
FLAME.call(MyApp.FFMpegRunner, fn ->
# I'm runner on a short-lived, temporary server
tmp_dir = Path.join(System.tmp_dir!(), Ecto.UUID.generate())
File.mkdir!(tmp_dir)
System.cmd("ffmpeg", ~w(-i #{vid.url} -vf fps=1/#{interval} #{tmp_dir}/%02d.png))
urls = VideoStore.put_thumbnails(vid, Path.wildcard(tmp_dir <> "/*.png"))
Repo.insert_all(Thumbnail, Enum.map(urls, &%{video_id: vid.id, url: &1}))
end)
endInstead of specifying node names(like :"[email protected]" as we did in our example, with FLAME you specify a pool name(MyApp.FFMpegRunner). The function in the second argument then runs on some node that's in that pool. It's very much like a GenServer call– the calling code doesn't have to know that it's running on a different machine.
So, I was trying to put together something that looks like the FLAME API but rather than FLAME spinning up machines, the idea was to let existing nodes in your cluster join pools.
Our API
This is how you'd run any arbitrary function in a pool:
iex> foo = 1212
iex> DistributedPool.call(MyApp.PipelinePool, fn ->
"#{node()} says foo is #{foo}"
end)
{:ok, "[email protected] says foo is 1212"}And this is how you'd start an OTP process given a child specification.
task_spec = %{
id: :auto_terminating_task,
start: {Task, :start_link, [fn ->
Process.sleep(5000)
end]},
restart: :temporary
}
{:ok, pid} = DistributedPool.place_child(MyApp.PipelinePool, task_spec)Implementation overview
For a given pool(call it the FFMpegPool ), the idea is that nodes that are part of the pool start a DynamicSupervisor This DynamicSupervisor would then join a process group(using pg) with its fellow DynamicSupervisors in the pool.
We use pg because this process group spans our cluster– so we can create a list of each DynamicSupervisor that we started for the FFMpegPool.
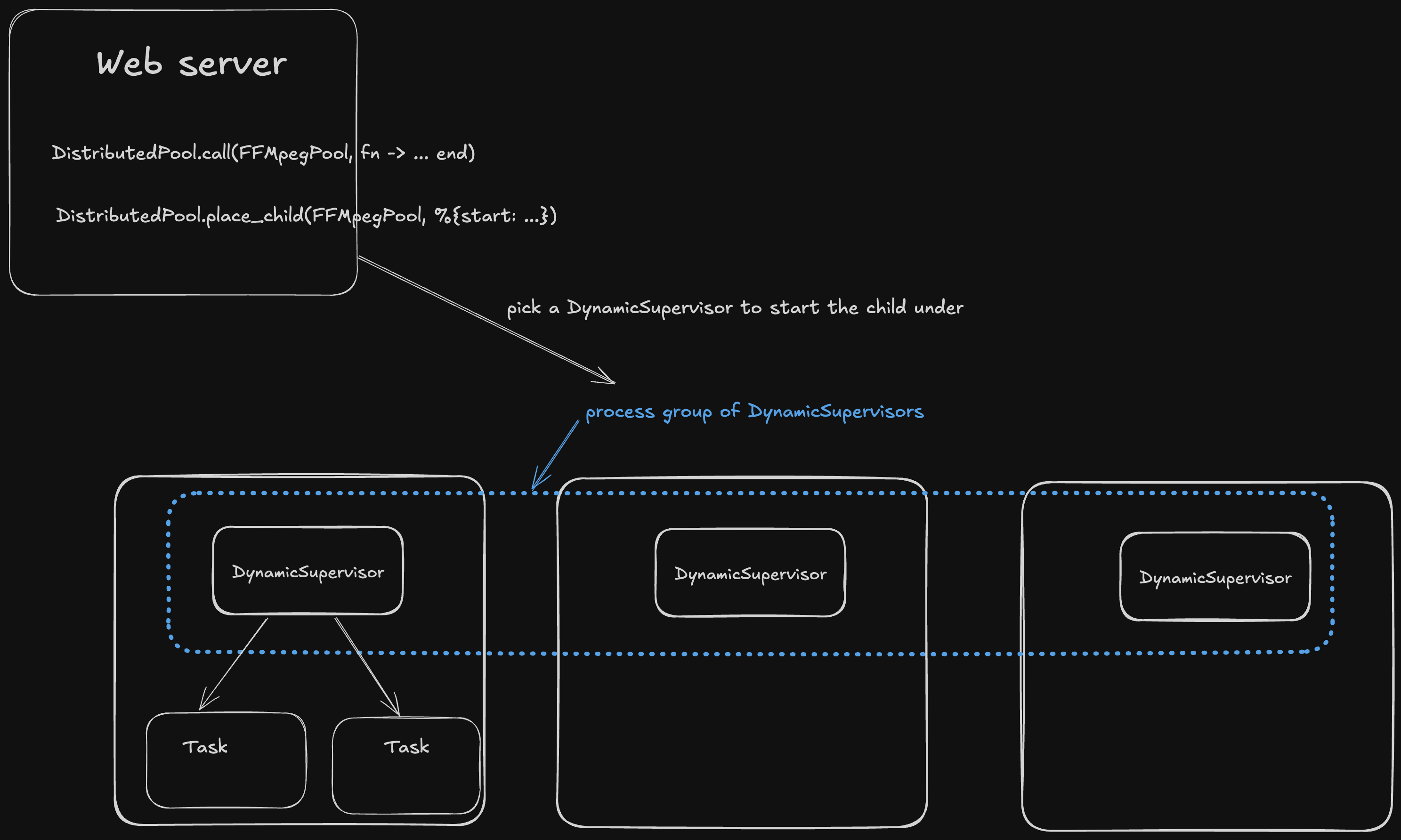
When there is a need for us to run some code in the pool, we get the PID of one of these DynamicSupervisors, and start the child under that supervisor.
Joining the pool
def start_link([pool_name: pool_name] = opts) do
DynamicSupervisor.start_link(__MODULE__, opts, name: pool_name)
end
def init([pool_name: pool_name] = _opts) do
max_concurrency = Application.get_env(pool_name, :max_concurrency, 5)
:pg.join(pool_name, self())
DynamicSupervisor.init(
strategy: :one_for_one,
max_children: max_concurrency
)
endAs mentioned above, our DynamicSupervisor joins a process group using :pg.join for the pool. Other than that, the other interesting detail is max_children-- since each process is presumable resource-intensive, we want to limit the number of processes that spawned.
Finding a supervisor
pg makes this very simple:
@doc """
Get all supervisors in a pool.
"""
def get_pool_supervisors(pool_name) do
:pg.get_members(pool_name)
endBut we have to pick which supervisor is the best to run our process under.
I went with a fairly naive approach– I query each supervisor in the pool for the number of active children and find the one with the least number of children:
@doc """
Get a supervisor from the pool with the least number of children.
"""
def get_available_supervisor(pool_name) do
max_concurrency = Application.get_env(pool_name, :max_concurrency, 5)
supervisors = get_pool_supervisors(pool_name)
case supervisors do
[] ->
{:error, :no_supervisors_available}
supervisors ->
# Find supervisor with least number of children
case find_least_loaded_supervisor(supervisors) do
{supervisor, count} when count < max_concurrency ->
{:ok, supervisor}
_ ->
{:error, :all_supervisors_at_capacity}
end
end
end
defp find_least_loaded_supervisor(supervisors) do
supervisors
|> Enum.map(fn sup -> {sup, get_supervisor_child_count(sup)} end)
|> Enum.min_by(fn {_sup, count} -> count end)
endQuerying each supervisor(which live on different nodes) for every request is certainly a bit wasteful, but my setup only has a handful of nodes at the moment so I've stuck with this approach for now.
Placing children under the supervisor
Finally let's look at the place_child implementation:
@doc """
Places any process in the specified pool using a supervisor selected from the pool.
"""
def place_child(pool_name, child_spec) do
case get_available_supervisor(pool_name) do
{:ok, supervisor} ->
%{start: start} = child_spec = Supervisor.child_spec(child_spec, [])
caller = self()
gl = Process.group_leader()
rewritten_start = {__MODULE__, :start_child_inside_sup, [start, caller, gl]}
wrapped_child_spec = %{child_spec | start: rewritten_start, restart: :temporary}
DynamicSupervisor.start_child(supervisor, wrapped_child_spec)
{:error, reason} ->
{:error, reason}
end
end
@doc """
Starts the child process with proper context
TODO: link `caller_pid`
"""
def start_child_inside_sup({m, f, a}, _caller, group_leader) do
# We switch the group leader, so that the newly started
# process gets the same group leader as the caller
initial_gl = Process.group_leader()
Process.group_leader(self(), group_leader)
try do
case apply(m, f, a) do
{:ok, pid} = result when is_pid(pid) ->
result
other ->
other
end
after
Process.group_leader(self(), initial_gl)
end
end
Before starting the child, we wrap the child spec in a function that sets the Process group leader to that of the caller. This ensures that output from the child is piped to the caller process.
We also set the restart strategy to :temporary to avoid restarting children. Here, I'm just copying a design decision from FLAME: if you want the child to get restarted, the caller needs to monitor the process.
The call function is implemented by placing a Task under our chosen DynamicSupervisor using place_child:
@doc """
Executes the given function in a worker process managed by the pool.
Similar to Task.async/1 but runs in a pooled worker.
Returns {:ok, result} or {:error, reason}
"""
def call(pool_name, fun) when is_function(fun, 0) do
parent = self()
child_spec = %{
id: make_ref(),
start:
{Task, :start_link,
[
fn ->
try do
result = fun.()
Process.send(parent, {:result, result}, [])
rescue
e -> Process.send(parent, {:error, e}, [])
end
end
]},
restart: :temporary
}
case place_child(pool_name, child_spec) do
{:ok, pid} ->
ref = Process.monitor(pid)
receive do
{:result, result} ->
Process.demonitor(ref, [:flush])
{:ok, result}
{:error, reason} ->
Process.demonitor(ref, [:flush])
{:error, reason}
{:DOWN, ^ref, :process, ^pid, _reason} ->
{:error, :worker_crashed}
end
{:error, reason} ->
{:error, reason}
end
end
endDifferences from FLAME
This system has a few things that work differently from FLAME:
- In FLAME, there is a
Terminatorprocess running that is responsible for enforcing deadlines specified by the application on processes(among other responsibilities). - You can also optionally link the caller process to the child process in FLAME. For my use-case, I wanted the lifecycle of the child process to be independent of the parent process(and node), so I don't link them.